playwright入门
目录
一、简介
Playwright是微软开源的一个UI自动化测试工具,一个用于 Web 测试和自动化的框架。它可以通过单个 API 自动执行 Chromium,Firefox 和 WebKit 浏览器,同时支持以无头模式、有头模式运行。
二、playwright特性
1、支持所有主流浏览器
1.1、支持所有主流浏览器:基于 Chromium 内核的 Google Chrome 和 Microsoft Edge 浏览器), WebKit 内核的 Apple Safari 和 Mozilla Firefox 浏览器,不支持 IE11。 1.2、跨平台:Windows、Linux 和 macOS
1.3、可用于模拟移动端 WEB 应用的测试,不支持在真机上测试。
1.4、支持无头模式(默认)和有头模式
2、快速可靠的执行
2.1、自动等待元素
2.2、Playwright 基于 Websocket 协议,可以接受浏览器(服务端)的信号。selenium 采用的是 HTTP 协议,只能客户端发起请求。
2.3、浏览器上下文并行:单个浏览器实例下创建多个浏览器上下文,每个浏览器上下文可以处理多个页面。
2.4、有弹性的元素选择:可以使用文本、可访问标签选择元素。
3、强大的自动化能力
3.1、playwright 是一个进程外自动化驱动程序,它不受页面内 JavaScript 执行范围的限制,可以自动化控制多个页面。
3.2、强大的网络控制:Playwright 引入了上下文范围的网络拦截来存根和模拟网络请求。
3.3、现代 web 特性:支持 Shadow DOM 选择,元素位置定位,页面提示处理,Web Worker 等 Web API。
3.4、覆盖所有场景:支持文件下载、上传、OOPIF(out-of-process iframes),输入、点击,暗黑模式等。
三、安装
安装playwright库
pip install playwright
安装浏览器驱动文件
playwright install
win7安装 playwright 常见的问题解决方法见:https://jiner.wang/win7%e5%ae%89%e8%a3%85-playwright-%e5%b8%b8%e8%a7%81%e7%9a%84%e9%97%ae%e9%a2%98/
四、基本使用方法
4.1、自动等待
Playwright 在发起操作前在元素上执行一系列可操作性检查(actionability checks),确保这些操作的行为与预期一样。它自动等待所有相关检查通过,然后执行请求的操作。如果在给定的超时时间内,需要的检查没通过,那么操作以 TimeoutError 失败。
比如,对于 page.click(selector, **kwargs),Playwright 将确保:
- 元素被附加(Attached)到 DOM
- 元素是可见的(Visible)
- 元素是稳定的(Stable),比如在非动画或已完成的动画中
- 元素接收事件(Receives Events),比如没被其它元素遮挡
- 元素是启用的(Enabled)
Text content
content = await page.textContent('nav:first-child');
expect(content).toBe('home')4.2、元素定位
4.2.1、文本选择定位器
特点:
1、模糊匹配
2、不缺分英文的大小写
3、如果存在多个会报错
示例:
page.locator("text=ABC").click()
page.locator("text='ABC'").click()
page.locator("'ABC'").click()text=ABC与text='ABC'的区别:
没有加引号(单引号或者双引号):模糊匹配 并 对大小写不敏感的 有引号:精确匹配 并 对大小写敏感
也可使用比较精准的方式,点击 id=main-nav-menu 包含的元素里文本='社区'的元素。
page.locator("#main-nav-menu :text('社区')").click()4.2.2、CSS 选择器定位
<span class="bg s_btn_wr">
<input type="submit" id="su" value="百度一下" class="bg s_btn">
</span>定位上述元素的方法:
#方法一:根据classname定位
page.locator(".bg.s_btn").click()
#方法二:根据id定位
page.locator("#su").click()通过属性定位,点击属性中存在 href="/topics"的元素
page.locator('[href="/topics"]').click()通过属性精准定位:点击 ID=header元素下的 href="/game/live"的元素
page.locator('#header [href="/game/live"]').nth(1).click()注意:如果有多个严肃匹配时
# 正确的做法,应该指定位置或者使用定位器的过滤器
locator.first, locator.last, locator.nth(index)
page.locator("#nav-bar .contact-us-item").click()4.2.3、CSS 选择器 + 文本
可以使用 CSS 选择器结合文本值进行筛选,比较常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
#查找标签p,文本内容为 开通会员 的元素进行点击
page.locator("p:text('开通会员')").nth(1).click()
#查找标签p,文本内容包含 开通 的元素进行点击
page.locator("p:has-text('开通')").nth(1).click()4.2.4、CSS 选择器 + 节点关系
#选择 class 为 base-title 的节点,且该节点还要包含 text 为 热门推荐 的子节点。
page.locator(".base-title:has(:text('热门推荐'))").click()另外还有一些相对位置关系,比如 left-of 可以指定位于某个节点左侧的节点,示例如下
#选择的一个 input 节点,并且该 input 节点要位于classname为 nav-actio 的节点的左侧。
page.locator("p:left-of(.nav-action)").nth(1).click()4.2.5、根据元素可用
page.locator("button:visible").click()
page.locator("button >> visible=true").click()4.2.6、选择符合其中一个条件的元素
#选择input元素,文本内容为 百度一下 或者文本内容为 Sign in
page.locator('input:is(:text("百度一下"), :text("Sign in"))').click()关于更多选择器的用法,可以参考官方文档:https://playwright.dev/python/docs/selectors。
4.3、断言
Playwright Test 使用 expect 库进行测试断言。它提供了很多匹配器, toEqual, toContain, toMatch, toMatchSnapshot 等等。
4.3.1、文本内容
page_locator=page.locator('.title-content-title').nth(0)
expect(page_locator).to_have_text("提振消费年味足")4.3.2、value属性
page_locator=page.locator('#su')
expect(page_locator).to_have_value("百度一下")4.3.3、根据元素属性
page_locator = page.locator('#kw')
expect(page_locator).to_have_attribute("autocomplete", "off")4.3.4、根据是否包含className
expect(locator).to_have_class("selected row")4.3.5、根据是否包含css
expect(locator).to_have_css("display", "flex")4.3.6、根据复选框是否checked
expect(locator).to_be_checked()关于更多断言的用法,可以参考官方文档:https://playwright.bootcss.com/docs/assertions
4.4、page
Page 就是单独的一个浏览器 tab 标签创建
page = context.new_page()
page.goto("https://www.jd.com/")page 有多个常用的方法:on、goto、fill、inner_html、content、query_selector、query_selector_all 等等。
1、goto():用于跳转网址。
2、on():事件的监听,可以用来监听浏览器中发生的任何事件,如:close、console、download、request、response 等等。
示例:用来监听 request 请求,打印出 post 的提交数据和请求地址:
def on_request(request):
print('--------start---------')
print(request.url)
print(request.post_data)
print('--------start---------')
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
page.on('request', on_request)
page.goto("https://www.baidu.com/")
context.close()
browser.close()3、fill() 用于填写 input 框,在百度搜索框中写入 111:
page.fill("input[name=\"wd\"]", "111")4、inner_html()、content() 获取页面源代码:
page.inner_html('//html')
page.content()5、query_selector 选择一个节点,当匹配到多个节点,只会返回第一个,获取 class='toindex' 的文本:
handle = page.query_selector('.toindex')
print(handle.text_content())6、query_selector_all 选择所有的节点,获取百度页面上所有 input 的 name:
handles = page.query_selector_all('input')
for item in handles:
print(item.get_attribute('name'))五、脚本录制
使用Playwright无需写一行代码,我们只需手动操作浏览器,它会录制我们的操作,然后自动生成代码脚本。
下面就是录制的命令codegen,仅仅一行。
python -m playwright codegencodegen的用法可以使用--help查看,如果简单使用就是直接在命令后面加上url链接,如果有其他需要可以添加options。
Usage: playwright codegen [options] [url]
open page and generate code for user actions
Options:
-o, --output <file name> saves the generated script to a file
--target <language> language to generate, one of javascript, test, python, python-async, pytest, csharp, csharp-mstest, csharp-nunit, java (default: "python")
--save-trace <filename> record a trace for the session and save it to a file
-b, --browser <browserType> browser to use, one of cr, chromium, ff, firefox, wk, webkit (default: "chromium")
--block-service-workers block service workers
--channel <channel> Chromium distribution channel, "chrome", "chrome-beta", "msedge-dev", etc
--color-scheme <scheme> emulate preferred color scheme, "light" or "dark"
--device <deviceName> emulate device, for example "iPhone 11"
--geolocation <coordinates> specify geolocation coordinates, for example "37.819722,-122.478611"
--ignore-https-errors ignore https errors
--load-storage <filename> load context storage state from the file, previously saved with --save-storage
--lang <language> specify language / locale, for example "en-GB"
--proxy-server <proxy> specify proxy server, for example "http://myproxy:3128" or "socks5://myproxy:8080"
--proxy-bypass <bypass> comma-separated domains to bypass proxy, for example ".com,chromium.org,.domain.com"
--save-har <filename> save HAR file with all network activity at the end
--save-har-glob <glob pattern> filter entries in the HAR by matching url against this glob pattern
--save-storage <filename> save context storage state at the end, for later use with --load-storage
--timezone <time zone> time zone to emulate, for example "Europe/Rome"
--timeout <timeout> timeout for Playwright actions in milliseconds, no timeout by default
--user-agent <ua string> specify user agent string
--viewport-size <size> specify browser viewport size in pixels, for example "1280, 720"
-h, --help display help for command
Examples:
$ codegen
$ codegen --target=python
$ codegen -b webkit https://example.comoptions含义:
- -o:将录制的脚本保存到一个文件
- --target:规定生成脚本的语言,有
JS和Python两种,默认为Python - -b:指定浏览器驱动
例如,使用chromium驱动,在baidu.com搜索,并将录制脚本保存在playwright_demo.py文件中
python -m playwright codegen --target python -o D:\playwright_demo.py -b chromium https://www.baidu.com
命令行输入后会自动打开浏览器,然后可以看见在浏览器上的一举一动都会被自动翻译成代码
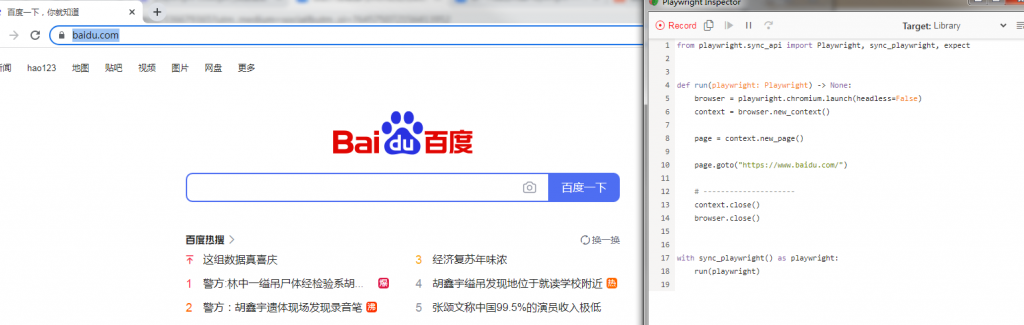
结束后自动关闭浏览器,保存生成的自动化脚本到py文件
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
page.locator("input[name=\"wd\"]").click()
page.locator("input[name=\"wd\"]").fill("dsd")
page.get_by_role("button", name="百度一下").click()
page.wait_for_url("https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=dsd&fenlei=256&rsv_pq=0xd0fd509e00009d6c&rsv_t=077fHbib4H1HibJyC0PA7i8ch1maggXwBBQT1b1lYMhxTkXHqQHR3NSwnu4a&rqlang=en&rsv_enter=0&rsv_dl=tb&rsv_sug3=4&rsv_sug1=2&rsv_sug7=100&rsv_btype=i&prefixsug=dsd&rsp=0&inputT=1649&rsv_sug4=2252")
page.locator("form[name=\"f\"]").get_by_text("").click()
page.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)六、同步&异步
6.1、同步
依次打开两个个浏览器,前往baidu搜索,截图后退出
from playwright.sync_api import Playwright, sync_playwright, expect
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox]:
browser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://baidu.com/')
page.screenshot(path='example-'+browser_type.name+'.png')
browser.close()
6.2、异步
异步操作可结合asyncio同时进行两个浏览器操作。
import asyncio
from playwright.async_api import Playwright, async_playwright, expect
async def main():
async with async_playwright() as p:
for browser_type in [p.chromium, p.firefox]:
browser = await browser_type.launch(headless=False)
page = await browser.new_page()
await page.goto('http://baidu.com/')
await page.screenshot(path='example'+browser_type.name+'.png')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())七、移动端
playwright还可支持移动端的浏览器模拟,下方示例为模仿iphone 12 pro 打开浏览器
import time
from playwright.sync_api import sync_playwright
def run(playwright):
chrom=playwright.chromium
iphone=playwright.devices['iPhone 12 Pro']
browser = chrom.launch(headless=False)
# context=browser.new_context(**iphone,locale='zh-CN', geolocation={ 'longitude': 12.492507, 'latitude': 41.889938 },
# permissions=['geolocation'])
context = browser.new_context(**iphone)
page=context.new_page()
page.goto("http://www.baidu.com")
print(page.context)
time.sleep(5)
browser.close()
with sync_playwright() as playwright:
run(playwright)总结
playwright相比已有的自动化测试工具有很多优势,比如:
- 跨浏览器,支持Chromium、Firefox、WebKit
- 跨操作系统,支持Linux、Mac、Windows
- 可提供录制生成代码功能,解放双手
- 可用于移动端
目前存在的缺点就是生态和文档还不是非常完备,比如没有API中文文档、没有较好的教程和示例供学习